 |
IMS 어휘교환(VDEX) - XML 바인딩 |
| 발행일 | 2009년 00월 00일 |
| 최신 버전 | IMS 어휘교환 표준 – XML 바인딩 버전 1.0 |
| 이전 버전 |
Copyright © IMS Global Learning Consortium 2007. All Rights Reserved.
이 표준을 배포하거나 제품 또는 서비스 제공을 위해서 활용하고자 한다면, IMS Korea 표준화 포럼 사무국(한국교육학술정보원)에 승인 요청을 하고 이메일을 통해 승인을 받아야 한다. IMS 정식회원 및 기부회원, 개발자 네트워크는 상기의 저작권 공지사항과 이 문장을 사본에 포함시키는 조건 하에 이 표준을 배포 및 활용할 수 있다. 그러나 저작권 공지사항 또는 IMS 명칭이 표기된 부분을 삭제하는 등, 이 표준을 훼손하는 행위는 금지된다. 단, IMS가 승인한 프로젝트그룹의 감독 하에 IMS 표준을 수정하는 경우는 예외적으로 허용된다. 상기 부여된 제한된 승인 내용은 영속적이며, IMS 또는 후임기관 그 누구라도 라이센스를 취소할 수 없다. 이 표준은 어떠한 보증도 하지 않으며, 특히 불침해에 대한 그 어떤 보증도 하지 않는다. 이 표준의 사용에 대한 책임은 온전히 사용자에 의하며, 그 어떤 컨소시엄이나 제공 주체도 이 표준을 사용함으로써 제3자가 직간접적으로 입을 수 있는 피해에 대해 책임지지 않는다.Copyright © 2007 by IMS Global Learning Consortium, Inc. All Rights Reserved.
1)IMS 지적재산권 웹 페이지 : http://www.imsglobal.org/ipr/imsipr_policyFinal.pdf
| 원안작성 협력기관 : 한국교육학술정보원(IMS Korea 표준화 포럼) | |||
| 성 명 | 근 무 처 | 직 위 | |
| (위 원 장) | 황대준 |
성균관대학교 |
교수 |
| (실무위원) | 김성윤 |
(주)포씨소프트 |
이사 |
| 김 현 |
(주)씨티유니온 |
차장 | |
| 유욱종 |
(주)다울소프트 |
부장 | |
| 조성현 |
테크빌닷컴(주) |
부사장 | |
| 조용상 |
한국교육학술정보원 |
팀장 | |
| 차남주 |
(주)디유넷 |
부사장 | |
| 최성기 |
SK C&C |
과장 | |
| (자문위원) | 권희춘 |
수원여대 |
교수 |
| 김종현 |
계원디자인예술대학 |
교수 | |
| 김현진 |
한국교원대학교 |
교수 | |
| 손진곤 |
한국방송통신대학교 |
교수 | |
| 정광식 |
한국방송통신대학교 |
교수 | |
| 한태인 |
(주)메디오피아 |
부사장 | |
| (간 사) | 신성욱 |
한국교육학술정보원 |
연구원 |
머 리 말
이 표준은 한국의 이러닝 분야 디지털 콘텐츠의 공유 및 유통 체제 확립을 위해 IMS Global Learning Consortium(이하 GLC)의 Vocabulary Definition Exchange 표준을 기초로 작성한 IMS Korea 단체표준이다. 이 표준은 한국의 문화적, 교육적, 언어적 특수성 등을 감안하여 현지화 등 확장을 고려하여 작성되었다. 또한 이 표준을 실제 구현할 때 부분적으로 선택하여 적용할 수 있도록 필수와 선택 영역이 구분되어 있으므로 목적에 따라 선별적인 적용이 가능하다. 이 표준은 다양한 분야나 시스템상에서 사용되는 여러 종류의 어휘들에 대한 표현법을 정의하고 있으며 어휘교환 표준을 사용해 표현이 가능한 다양한 어휘 유형이 소개된다. 그러나 IMS 어휘교환 표준은 일반적으로 사용되고 있는 모든 어휘 유형을 표현하는 데에 사용될 수 있는 것은 아니며, 시스템상에서 해석이 가능한 비교적 심플한 용어들을 어휘단위로 구성할 때 쓰여질 수 있는 표현방식을 기술하는 데에 초점을 두었다. 따라서 이 표준은 시스템상에서 처리가 가능하도록 다양한 인간 언어 용어를 특정 목록으로 표현하는데 사용될 수 있다. 이 목록은 각 용어의 고유 의미와 활용 정보가 기술되어 있으며 이와 같은 용어들은 종종 시소러스(thesauri)의 형태로 수집된다. 이 표준은 다양한 임의적 관계 유형을 사용해 시소러스를 표현하는 것을 가능하게 한다. 이 표준은 멀티파트로 구성되며, 다음과 같은 세가지 표준 문서로 구성된다.- Part 1 : 정보 모델 (Information Model)
- Part 2 : XML 바인딩 (XML Binding)
- Part 3 : 활용 사례 및 실행 가이드 (Best Practice & Implementation Guide)
1 서론
1.1 네임스페이스와 바인딩 상황
이 문서는 IMS 어휘교환 표준 버전 1.0을 구성하는 하나의 부분으로 어휘교환 표준이 XML 버전 1.0을 사용해 어떻게 구현될 수 있는지에 대한 내용을 기술한다. 이 문서를 ‘어휘교환 XML 바인딩’이라 명한다. 이 바인딩 표준은 http://www.imsglobal.org/xsd/imsvdex_v1p0 에서 정의되는 네임스페이스를 준수한다.1.2 W3C XML 스키마 1.0 관리 문서
스키마란 XML 인스턴스에서 요소간의 결합방식을 표시하기 위한 요소 이름의 형식적인 표준이다. 어휘교환 표준은 W3C XML 스키마 1.0(일종의 XSD 파일) 형태의 관리 문서를 포함하지만 문서 유형 정의(DTD)는 포함하고 있지 않다. 이는 XML 표준이 진화되고 있음을 보여주는 것이며 유연성과 정확성 때문에 W3C XML 스키마 1.0이 보편적으로 적용되고 있음을 나타내는 것이다. 이 문서는 바인딩 자체보다는 바인딩이 되는 방식을 설명하는 참조 자료로서 W3C XML 스키마 1.0 유형의 ‘imsvdex_v1p0.xsd’ 파일을 포함한다. 일부 XML 편집자들은 이러한 스키마를 사용하여 개발자가 XML 파일을 생성할 때 XML 파일내의 다양한 위치에 적합한 유형의 값을 입력할 수 있도록 가이드 해준다. 또한 일부 개발자들은 이 스키마를 자신이 기존에 생성한 XML 인스턴스의 구성형태가 적합한지 검증하는데 사용할 수 있으며, 또한 기존 XML 인스턴스에 어휘교환 XML 바인딩 규칙에 유효한 확장을 할 수 있다. 이 표준의 사용자들은 W3C XML 스키마 1.0를 구현하는 방법에 있어 유효 파서는 달라질 수 있고, 주어진 XML 인스턴스 문서가 유효한지의 여부는 유효 파서에 의해 입증되는 경우가 거의 없거나 전혀 없다는 점을 명심해야 할 것이다. 스키마 구조에 대한 세부사항은 이 문서의 적용범위에서 벗어난다. 바인딩과 함께 제공되는 W3C XML 스키마 1.0 관리 문서는 다음 원칙을 준수함과 동시에 생성되었다.- 그 밖의 어떠한 다른 네임스페이스도 참조하지 않는다. 그 이유는 표준이 현재 발전을 거듭하고 있기 때문에 다른 유형의 네임스페이스에 대한 참조를 허용한다는 것은 표준이 진화하는데 방해요소가 될 수 있기 때문이다.
- Microsoft XML Parser version 4
- Microsoft .Net Framework 1.1
- XML Spy version 4.4
- XML Authority 2.2 (인스턴스 유효성 제외)
- Xerces for Java 2.4.0
<?xml version=‘1.0’ encoding=‘utf-8’?>
<vdex profileType=‘lax’ xmlns=‘http://www.imsglobal.org/xsd/imsvdex_v1p0’
xsi:schemaLocation=‘http://www.imsglobal.org/ imsvdex_v1p0 imsvdex_v1p0.xsd’
xmlns:xsi=‘http://www.w3.org/2001/XMLSchema-instance’>
1.2.1 요소의 순서
XML 요소가 다른 요소들의 목록을 저장하는 컨테이너인 경우, W3C XML 스키마 1.0을 사용할 때 그 목록에 있는 요소의 순서를 정의하는 것이 유용할 경우가 많다. 이들 요소의 순서를 정하는 작업은 XML 문서의 유효성을 위해 반드시 지켜져야 한다. 하지만 정보 모델은 요소에 대한 순서를 정의하지 않는다. 왜냐하면 IMS 어휘교환 프로젝트 팀은 바인딩이 특정 요소에 대한 순서 없이 표현될 수 있도록 허용하는 W3C XML 스키마 1.0 기반의 구성방법을 고려했지만, 광범위하게 사용되고 있는 XML 파서를 이용해 테스트해 본 결과 이 목표(특정 요소에 대한 순서 없이 바인딩을 표현하는 것)를 달성하기 위해 필요한 활용 사례에 대한 정보가 불충분했다. 이러한 이유로 실용주의적 관점에서 순서가 정해진 바인딩을 생성하기로 결정했다. 위와 같은 제약이 향후에 완화될 가능성, 즉 XML 파서 개발 또는 보다 제한적이지 않은 XML 스키마 언어를 부분적으로 도입함으로써 야기되는 가능성을 고려하기 위해 사용자가 유의해야 할 사항은 다음과 같다.1.2.2 반복 요소
XML 내의 특정 위치에 이미 사용되고 있는 요소를 같은 위치에 반복하여 입력하면 기본적으로 요소에 대한 비순서적 목록이 생성된다. 입력된 순서가 중요한 것은 아니지만, 특정 용어 또는 전체 어휘에 ‘orderSignificant’ 특성이 설정되어 있는 경우는 예외이다. 어휘교환의 정보 모델을 참조하기 바란다. 어휘교환 XML 바인딩에서 반복되는 모든 다른 요소들을 해석할 때는 순서에 구애 받지 않으며 그 예는 다음과 같다.<title>
<langstring language=‘en’>Title</langstring >
<langstring language=‘es’>Título</langstring >
</title>
위의 예는 ‘Title’을 각각 다른 언어로 나타낸 것으로써 순서가 중요하지 않다.
1.2.3 IMS 어휘교환 바인딩 인스턴스 위치
http://www.imsglobal.org/xsd/imsvdex/에서 발견되는 xsd 파일은1 IMS 어휘교환 정보 모델의 표준 요소 및 값의 인스턴스를 바인딩 하는 현재 사용이 가능한 버전의 XML 스키마일 것이다. 주의사항: 이들 파일은 어휘교환 버전이 업그레이드 될 때 변경된다. 각 IMS 어휘교환 바인딩에 있는 버전화된 인스턴스들은 해당 버전 바인딩의 모든 메이저 또는 마이너 배포를 포함해 ‘http://www.imsglobal.org/xsd/imsvdex/vmpn/’ 에서 찾을 수 있으며, 여기에 버전화된 표준 인스턴스에 대한 저장 폴더 이름은 vmpn이다. 이는 다른 과거 버전과 마찬가지로 가장 최근 버전에도 적용된다. 이 공개 초안을 지속적으로 복사할 수 있지만, 이름은 imsvdex_v1p0pd.xsd 등으로 한다. IMS 어휘교환 표준 1.0 버전의 다양한 바인딩 인스턴스에 대한 XML 스키마 파일 비표준 예제는 다음의 주소에서 찾을 수 있다(http://www.imsglobal.org/xsd/imsvdex/v1p0/).1.2.4 XML 스키마 파일 명명 규칙
IMS 어휘교환은 XML 스키마의 인스턴스 구문 모델인 ‘imsvdex_vmpn[pr[ps]][pd].xsd’에 따라 명명된다. 이 모델에 대한 설명은 다음과 같다.- ‘imsvdex_’는 그 파일이 IMS 어휘 정의 교환 표준에 속한다는 것을 의미한다.
- ‘vm’은 바인딩 인스턴스가 정의하는 IMS 어휘교환 표준의 메이저 버전으로, ‘m’는 메이저 버전의 숫자이다.
- ‘pn’은 바인딩 인스턴스가 정의하는 IMS 어휘교환 표준의 마이너 버전(minor version)을 의미하는 것으로, ‘n’은 마이너 버전 숫자이다.
- [pr[ps]]은 메이저 및 마이너 배포 숫자들의 선택 가능한 세트로(파일 이름의 일부가 아닌 괄호로 표시되는), 선택 가능한 이 세트는 IMS 어휘교환 표준의 표준 인스턴스의 변경으로 유도되지 않는 스키마 인스턴스 자체에 대한 변경에 의해 좌우된다.
- ‘pr’은 마이너 버전을 추가로 갖지 않는 메이저 버전을 나타내는 것으로, 여기서 ‘r’은 메이저 버전 숫자이다.
- ‘ps’는 배포되는 마이너 버전을 나타내며, 여기에서 ‘s’는 마이너 버전 숫자이다. 메이저 버전 숫자는 마이너 버전 숫자의 증가에 따라 변경된다.
- ‘pd’는 공개 드래프트 표준 XML 스키마 바인딩 인스턴스를 나타낸다.
1.2.5 IMS의 바인딩 인스턴스 버전 명명 규칙
IMS 어휘교환 표준 바인딩은 그 바인딩 구조가 표준 인스턴스 전체에 걸쳐서 변경되었는가의 여부와 관계없이 항상 그 표준의 현재 버전 숫자를 나타낼 것이다. 이는 현재 바인딩 인스턴스의 파일 이름이 그 표준의 동일한 메이저 및 마이너 버전 숫자를 공유한다는 의미이다. 표준 버전과 관련된 사항의 변화 없이 바인딩 구조가 변경되면 바인딩의 파일명에 있는 메이저 또는 마이너 버전 레벨 부분이 올라가게 된다. 표준과 관련된 사항의 변화 없이 바인딩 구조가 변경되면 메이저 개정 레벨이 올라가게 된다. 구조 자체 또는 값과 연관된 의미의 변화 없이 구조 명칭 또는 그 값이 변경되면 마이너 개정 레벨이 올라가게 된다. 모든 버전 및 개정 작업은 바인딩 파일의 버전 정보에 반영되어 나타내어진다. 이 바인딩 파일은 http://www.imsglobal.org/xsd/imsvdex 에 그 최신버전이 업로드 되어있다. 구 바인딩은 개정 레벨 부분을 제외한 버전 레벨 부분 값을 기초로 imsvdex 파일 경로 내에서 그 위치가 옮겨진다. 각 XSD 파일은 내부적으로 그 버전을 표현한다. 다음은 그 예이다.<xs:schema targetNamespace=‘http://www.imsglobal.org/xsd/imsvdex_v1p0’ xmlns:xs=‘http://www.w3.org/2001/XMLSchema’ xmlns=‘http://www.imsglobal.org/xsd/imsvdex_v1p0’ elementFormDefault=‘qualified’ attributeFormDefault=‘unqualified’ version=‘1.0’>
1.3 유효 문자 세트
IMS 어휘교환 인스턴스는 RFC 2044에 정의된 대로 ISO 10646에서 정의된 것과 같은 문자세트의 UTF-8 인코딩을 사용해야 한다. 대체 인코딩도 가능하지만 상호운용성에 제약을 받을 수 있다. 숫자 개체 참조는 추천하지 않는다.1.4 IMS 어휘 정의 교환 표준 구성요소
이 문서는 IMS 어휘교환 표준 버전 1.0 XML 바인딩이다. 이 문서는 표준을 구성하는 세트의 하나의 부분이다. 다음의 부분들로 구성되어 있고 각 부분들은 고유의 적용범위를 가지고 있다. 정보 모델 표준의 핵심 부분을 설명하며 이 정보 모델을 기반으로 하는 모든 바인딩의 기준이 되는 부분을 기술한다. 의미론, 구조, 데이터 유형, 값 스페이스, 다중도, 필수여부(필수 또는 선택)와 같은 특성들에 대한 상세정보 또한 포함하고 있다. XML 바인딩 XML 버전 1.0을 기준으로 정보 모델의 바인딩을 설명하고 있으며 표준에 대한 참조에 의해서든 또는 표준이 지정한 네임스페이스 선언에 의해서든 이 바인딩을 사용하고자 하는 모든 XML 인스턴스의 토대가 된다. 바인딩의 오차 또는 누락이 발생하는 경우에는 정보 모델이 우선적으로 토대가 되어 참조되어야 한다. XML 바인딩 문서는 어휘교환 바인딩을 적용할 때 사용되어야 하는 W3C XML 스키마 1.0 기반의 관리 문서와 함께 제공된다. 활용 사례 및 실행가이드 정보 모델 및 XML 바인딩의 활용에 관한 비표준적인 지침을 제공한다. 이 문서는 어휘교환 표준의 상호운용성 및 내구성 증진을 목적으로 하는 다양한 표준활용 사례에 대한 지침을 포함해서 어휘교환 표준이 지지하는 방향으로 표준을 활용하고 있는 현재 진행 중인 사례들을 소개한다. 또한, 개념적 프레임워크가 어떻게 실제로 사용될 수 있게 매핑되는지를 나타내는 예시 및 이 표준과 관련된 IMS 표준들과 어휘교환 표준간의 관계를 식별하기 위한 예시가 제공된다. 반드시 따라야 하는 것은 아니지만 활용 사례 및 실행 가이드 문서에 포함된 지침을 따르는 것이 바람직하다.1.4.1 적합성 요구사항
정보 모델 및 바인딩 활용과 관련해 사용될 수 있는 테스트 명령문을 제공한다. 제공되는 명령문은 공식적인 성향을 띄는 적합성 테스트 및 증명 또는 비공식적 주장의 기초가 될 수 있다. 이 문서는 증명 또는 주장에 대한 공식 절차 및 방법에 대해 서술하지 않으며 단지 기준만을 제시한다.2 XML 스키마 바인딩에 대한 기술적 설명
이 장은 그래프 세그먼트를 사용해서 어휘교환 모델에 대한 XSD 바인딩의 XML 서식을 설명한다. 어휘교환 표준의 이론적인 서식을 갖추고 있는 XSD 문서는 이 표준의 비표준 부분으로 참조된다. 명확성 및 간결성을 위해 서술적인 설명보다는 그래프 구성조각을 사용함으로 표준 사용자의 친밀도와 선호도를 반영한다. XML 스키마 기반의 정보 또는 데이터 모델에서 표시하지 않는 명칭을 사용해 구조 개체를 생성할 필요한 경우가 종종 있다. 이런 특별한 구조화에서도 요소들에 대한 그룹화 및 사용함에 있어 데이터 모델의 정의를 따를 수 있다.| 그래픽요소의이해: 모서리가 각진 직사각형 = 요소 모서리가 둥근 직사각형으로 테두리가 붉은 색임 = 속성 사각형 반의 위쪽에 있는 굵은 글씨 명칭: 요소/속성 명칭 사각형 반의 아래 쪽에 있는 보통 글씨 명칭: 유형 명칭 요소, 속성, 또는그룹왼쪽에있는원을두른다중성표시: ? = 0..1 * = 0..n + = 1..n D = 0..1, 없는 경우 기본값과 함께 (속성에만) (표시가 없는 경우) = 1 분지선(Branching lines) (칼라 복사에서 붉은 색) (그룹화 모델) 꺾쇠 묶음 = ‘순서’ 삼각 묶음 = ‘보기선택’ (이 표준에서는 사용되지 않음) #wildCard 다른 네임스페이스로부터 나온 요소들이 어휘교환 인스턴스에 포함될 수 있는 위치를 나타낸다. 이들은 적절한 XML 네임스페이스를 선언해야 한다. |
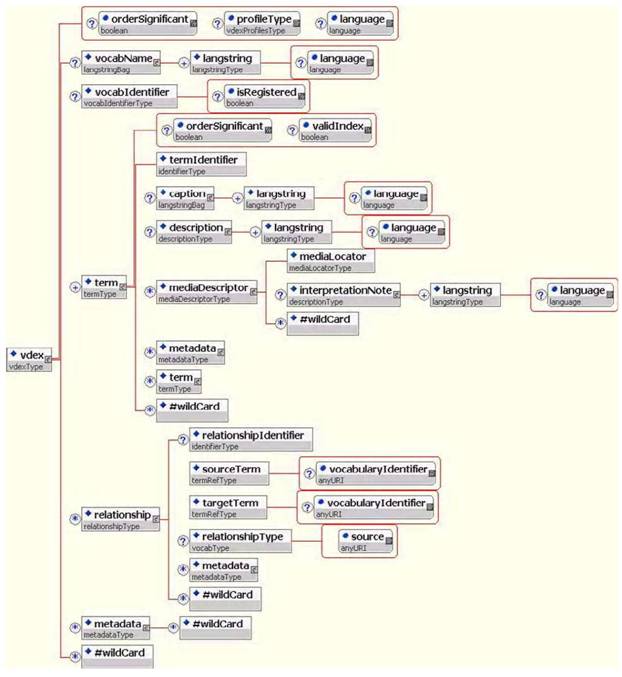
그림 2.1 XML 바인딩스키마도표
표 2.1 정보모델요소를위한바인딩명칭
|
정보모델명칭 |
elt/attr 을 포함하는 텍스트의 콘텐츠 유형 |
XML 바인딩요소또는속성명칭 |
| 순서 중요도 |
boolean |
@orderSignificant |
| 프로파일 유형 |
string (enumerated) |
@profileType |
| 어휘 명칭 |
- |
vocabName |
| 어휘 식별자 |
anyURI |
vocabIdentifier |
| 등록 상황 |
boolean |
@isRegistered |
| 기본 언어 |
language |
language |
| 용어 |
- |
term |
| 식별자 |
anyURI |
termIdentifier |
| 유효 인덱스 |
Boolean |
validIndex |
| 캡션 |
- |
caption |
| 설명 |
- |
description |
| 미디어 설명자 |
- |
mediaDescriptor |
| 미디어 위치 |
anyURI |
mediaLocator |
| 해석 설명 |
- |
interpreatationNote |
| 관계 |
- |
relationship |
| 식별자 |
anyURI |
identifier |
| 소스 용어/용어 식별자 |
anyURI |
sourceTerm |
| 소스 용어/어휘 식별자 |
anyURI |
sourceTerm/@vocabularyIdentifier |
| 타겟 용어/어휘 식별자 |
anyURI |
targetTerm |
| 타겟 용어/어휘 식별자 |
anyURI |
targetTerm/@vocabularyIdentifier |
| 관계 유형 |
- |
relationshipType |
| 관계 유형의 소스 |
anyURI |
@source |
| 관계 유형 값 |
string |
{relationshipType의 텍스트 내용} |
| 메타데이터 |
- |
metadata |
| 언어 문자열 |
- |
langstring |
| langstring의 언어 |
language |
language |
| Langstring의 내용 |
string |
{langstring의 텍스트 내용} |
| 주: ‘@’는 바인딩에서 쓰여지는 속성을 표시한다. | ||
|
요소 |
주 |
예제 |
| vdex | 이 요소는 네임스페이스 정보를 포함해야 한다. profileType 속성은 일종의 열거된 문자열로, 그 값은 반드시 어휘교환 정보 모델에 주어진 허용 값 목록에서 나온 것이라야 한다. |
<vdex profileType=‘lax’ xmlns=‘http://www.imsglobal.org/xsd/imsvdex_v1p0’ xsi:schemaLocation=‘http://www.imsglobal.org/imsvdex_v1p0 imsvdex_v1p0.xsd http://www.w3.org/XML/1998/namespace xml.xsd’ xmlns:xsi=‘http://www.w3.org/2001/XMLSchema-instance’> |
| vocabName | 적어도 하나의 langstring 이 있어야 한다. |
<vocabName>
<langstring language=‘en’>UK Driving Offence Codes</langstring>
</vocabName>
|
| vocabIdentifier | 어휘 콘텐츠 제약에 대한 내용은 2.1.1장 참조. |
<vocabIdentifier>URN:IMS-PLIRID-V0::6abd6e8f675fb87108db8cd0</vocabIdentifier> <vocabIdentifier>http://www.imsglobal.org/vocabularies/UK%20Driving</vocabIdentifier> |
| term | 적어도 하나의 용어가 존재해야 한다. | |
| termIdentifier | 어휘 콘텐츠 제약에 대한 내용은 2.1.1장 참조. termIdentifier 값은 어휘교환 인스턴스 내에서 반드시 고유한 것이라야 한다. |
<termIdentifier>exact</termIdentifier> |
| caption | 적어도 하나의 langstring 이 있어야 한다. |
<caption>
<langstring language=‘es’>Frenar en seco</langstring>
<langstring language=‘en’>Braking Hard</langstring>
</caption>
|
| description | 적어도 하나의 langstring 이 있어야 한다. | |
| mediaDescriptor | xml:base 는 사용될 수 없다. mediaLocator 자체로 리소스의 위치를 파악하기에 충분해야 한다. 만약 mediaDescriptor 가 사용된다면, mediaLocator 가 있어야 한다. | |
| relationship | 이 관계(relationship) 유형은 도메인 내의 값으로 표현된다. 소스는 ‘xs:anyURI’로 바인딩된다. 2.1.1장에선 이 관계가 강제하는 제약에 대해 설명하고 있다. 소스와 타겟 용어에 대한 어휘 식별자가 없다는 것은, 용어가 관계가 정의되는 어휘와 동일한 어휘 안에 나타난다는 것을 의미한다. NB: 이는 용어가 일종의 구성조각일 수 있기 때문에, 용어가 반드시 동일한 XML 인스턴스에 나타나야 한다는 것을 의미하지는 않는다. |
<relationship> <sourceTerm>sailboat</sourceTerm> <targetTerm>boat</targetTerm> <relationshipType source=‘http://www.imsglobal.org/vocabularies/iso2788_relations.xml’> BT</relationshipType> </relationship> |
| Metadata | 이 요소는 정의된 콘텐츠를 포함하지 않는다. 2.3장 참조. |
| 1 xml: prefix 의 사용과 네임스페이스 ‘http://www.w3.org/XML/1998/namespace’ 에서 정의하는 요소들에 대한 참조는 심각한 상호운용성 문제를 야기했는데, 이는 각기 다른 XML 파서에 의해 서로 다른 규칙이 적용됨으로 발생한 것이다. 이에 대해 W3C XML 스키마 1.0은 언어 코드에 대한 데이터 유형을 제공하였고 그 결과 XSD 내에서 xml:lang과 같은 동일한 제약을 직접적으로 적용하는 것이 가능해졌다. |
2.1 식별자 요소 콘텐츠
식별자에 대한 XML 스키마 데이터 유형은 ‘anyURI’ 이다. URI 또는 URI 참조에서 허용되지 않는 문자들은 XML 인스턴스를 생성할 때 RFC2396(차후 RFC2732로 개정됨)에 정의된 대로 제외되어야만 한다. 그러나 프로세스 중일 때에는 제외되지 않는다. RFC 2396에 정의되지 않은 문자들을 제외해야 하는 경우에는 RFC 2044에 정의된 변환 포맷을 사용해야 한다. 이 유형으로 제외할 때 ‘%xx’ 을 사용할 수 있지만 의무사항은 아니며, 이와 같은 RFC(를 따르는 경우 어휘교환 인스턴스에 ‘%xx’을 사용해야 한다. 그 예는 다음과 같다.<vocabIdentifier>http://www.imsglobal.org/vocabularies/UK%20Driving</vocabIdentifier>상기 내용은 에스케이프된 URL을 간단하게 보여주는 예로써, ‘http://www.imsglobal.org/vocabularies/UK Driving’에서도 동일한 내용을 찾을 수 있다. 유의사항 : 요소에 대한 내용이 의미적으로 URI여야 한다는 요구사항은 사용자가 URI 형식에 맞게 데이터를 입력해야 한다는 것을 의미하는 것은 아니다. 특히, 용어 식별자는 대체로 단순한 단문 형태의 텍스트 문자열이다. 활용 사례 및 실행 가이드에서는 식별자의 선택 및 활용의 실질적 접근법에 대해 설명한다.
2.1.1 식별자 고유성 및 관계 제약
용어 식별자는 반드시 고유한 것이라야 한다. 어휘교환 표준에선 W3C XML 스키마 1.0 정체성(identity) 제약 매커니즘, 즉 xs:unique 의 사용을 고려하였으나, 이번 어휘교환 표준 버전은 광범위하게 사용된 여러 XML 파서(parser)가 현재 이를 지원하지 않기 때문에 이 매커니즘을 사용하지 않는다. 바인딩에서 이것을 너무 일찍 사용했을 경우 상호운용성을 저해할 수도 있다. 하지만 사용자가 반드시 알아두어야 할 사항은 어휘교환 표준의 향후 버전에서는 이러한 유효성 제약을 XSD의 일부로 사용할 가능성이 높으며, 따라서 정보 모델의 요건 그리고 고유성과 관련된 현재 바인딩에 유의할 것을 적극 권장한다. 요구조건을 만족시키지 못하는 XML 인스턴스는 파서 유효성 확인의 통과 여부와 관계없이 부적합한 것으로 본다.2.2 프로파일 유형 활용
정보 모델은 보다 일반적인 어휘교환 모델에 대한 제한을 허용하는 다수의 프로파일 유형을 설명한다. 이 표준은 프로파일 유형을 사용할 때 XSD 문서 세트가 어떻게 XML 인스턴스를 통제하는가를 보여준다. 유의사항: 모든 인스턴스는 어떠한 프로파일 유형, 그리고 어떠한 프로파일 XSD가 사용되는지의 여부와 관계없이 동일한 XML 네임스페이스를 사용한다. 만약 ‘lax’ (이후 ‘프로파일화된 인스턴스’라고 함)의 범용형(generic type) 외의 유형이 사용된다면, 가능한 그에 일치하는 제한적인 XSD를 사용해야 한다. XSD에 대한 참조가 변동될 수 있다.- 범용(generic) XSD의 위치를 인스턴스로 파악하는 프로파일화된 인스턴스를 수신하는 어플리케이션은, 그 참조를 인스턴스에 선언된 프로파일과 일치하는 XSD의 위치를 파악하는 다른 참조로 교체할 수 있다.
|
프로파일유형 |
XSD 명칭 |
|
lax (범용 또는 비유형) |
imsvdex_v1p0.xsd imsvdex_v1p0_lax.xsd (these are identical) |
|
thesaurus (시소러스) |
imsvdex_v1p0_thesaurus.xsd |
|
hierarchicalTokenTerms |
imsvdex_v1p0_hierarchical.xsd |
|
glossaryOrDictionary |
imsvdex_v1p0_glossary.xsd |
|
flatTokenTerms |
imsvdex_v1p0_flat.xsd |
2.3 메타데이터 포함
메타데이터는 <metadata> 요소 내에 포함된다. 어떠한 콘텐츠도 이 요소 내에서 명확하게 정의될 수 없다. 어휘교환 표준의 활용 사례 및 실행 가이드 문서는 스키마 선택에 관한 몇 가지 사항들에 대해 언급했으나, 이는 임의 스키마(arbitrary schema)에 대한 컨테이너이다. 기술적으로 XML 네임스페이스를 이용해 XML을 확장하기 위해서 사용될 때와 마찬가지로 메타데이터는 동일한 매커니즘을 사용하여 포함된다. 4.2장에서는 이 매커니즘을 논의하고, 메타데이터의 예제는 활용 사례 및 실행 가이드에 실려 있다.3 프로파일 유형에 대한 바인딩 제약
이 장은 2장에서와 마찬가지로 프로파일 유형이 사용될 때 XML로 묶인 데이터가 어떻게 표현되어야 하는가를 보여주는 도표를 제공한다. 이들 도표는 범용 XML 바인딩에 어휘교환 정보 모델에서 설명된 제약을 적용하는 내용에 대해 명확하게 설명하고 있다.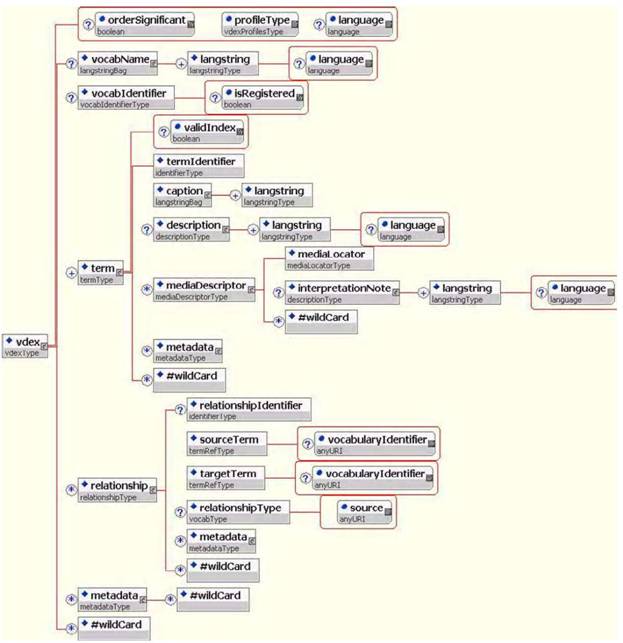
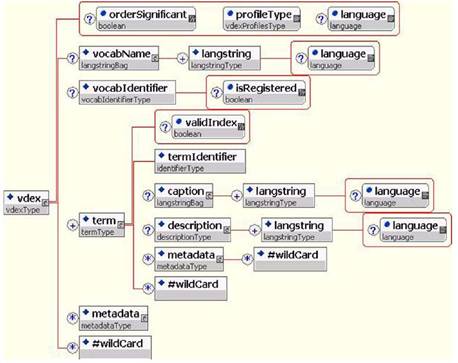
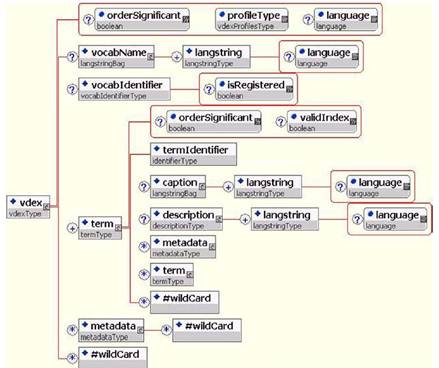

4 확장성
IMS 어휘교환 표준이 적용되는 일부 경우에는 정보 모델 및 XML 바인딩에 정의된 요소 세트가 요구사항을 모두 충족하기에는 너무 제한적이라는 것이다. IMS 어휘교환 표준의 정보 모델에서 확장성에 대한 구체적인 설명은 제시되지 않았다. 이 장은 XML 기반의 인스턴스를 사용해 확장성을 달성하는 방법에 대해 기술한다. 이 장은 바인딩에 국한된 내용이 아니며 아래 설명된 네임스페이스 확장 매커니즘은 W3C XML 스키마 1.0 의 다양한 활용 사례 및 활용 방법으로부터 발생할 수 있는 제약조건 등을 포함한다.4.1 문서 유형 정의를 활용한 확장
문서 유형 정의(DTD)는 이 표준과 함께 배포되지 않으며, 그 사용을 권장하지 않는다. W3C XML 스키마 1.0은 아래 설명된 자신의 네임스페이스로 만들어진 확장 매커니즘과 함께 사용해야 한다.4.2 네임스페이스된 요소 확장 매커니즘
추가 요소를 포함시켜 확장하는 것은 다음 위치에서 가능하며, ‘#wildCard’로 다양한 XML 바인딩 도표 내에서 식별할 수 있다. 다음 조건을 따른다.- 확장되는 요소는 반드시 이 표준에 정의되어 있는 요소를 따라야 한다.
- 확장되는 요소는 네임스페이스 선언을 포함하는데, 이는 그 포함요소(즉, 현재 경우 http://www.imsglobal.org/xsd/imsvdex_v1p0이 아니다)와는 다른 선언이다. 특정 네임스페이스가 없는 경우에 무효 네임스페이스(xmlns=‘‘“)를 사용할 수 있다.
<metadata>
<imsmd:lom>
<imsmd general>
<imsmd:title>
<imsmd:langstring language=‘en’>Example</imsmd:langstring>
</imsmd:title>
</imsmd general>
</imsmd:lom>
</metadata>
(접두어 imsmd가 xmlns:imsmd=http://www.imsglobal.org/xsd/imsmd_rootv1p2p1에 의해 앞서 선언된 경우)
그리고,
<metadata>
<lom xmlns=‘http://www.imsglobal.org/xsd/imsmd_rootv1p2p1’>
<general>
<title>
<langstring language=‘en’>Example</langstring>
</title>
</general>
</lom>
</metadata>
4.3 네임스페이스된 속성 확장 매커니즘
4.2 의 네임스페이스된 속성 확장 매커니즘과 유사한 매커니즘을 사용해 다음 어떤 요소에든 속성을 추가할 수 있다. 이는 다시 그 속성의 네임스페이스가 상위 요소와 달라야 한다는 요구조건을 따른다. 요소들의 속성 확장은 예를 들면, 특정 어플리케이션이 적절하게 해석 및 처리될 수 있도록 권한을 지정하기 위해 사용될 수 있지만 해석이 불가능한 시스템에서도 광범위하게 처리하는 것을 허용한다.4.4 제한 및 조건
앞서 설명된 바와 같이 바인딩 인스턴스의 확장을 위한 매커니즘 이외에 다른 매커니즘은 허용되지 않는다. 그 내용은 다음과 같다.- IMS 어휘교환 XML 스키마 정의 파일(XSD)을 수정하지 않는다.
- IMS 어휘교환 네임스페이스 내의 요소를 수정하지 않는다.
- IMS 어휘교환 네임스페이스 내에 있도록 지정된 인스턴스 문서의 모든 요소들은 이 바인딩 설명 문서에 제공된 그 요소의 정의와 정확히 일치해야 한다.
- 다른 네임스페이스의 요소들은 IMS 어휘교환 네임스페이스(XML 스키마 대체 그룹 메커니즘을 통해, 또는 다른 그 어떤 메커니즘을 통해)안의 요소를 대신하지 않는다.
- IMS 어휘교환 네임스페이스 내의 요소 및 속성을 위해 정의된 열거(enumeration)는 IMS 어휘교환 네임스페이스 안에서 확장되거나 제한될 수 없다.
부속서 A (참고)
추가 리소스 IEEE 1484-12.1-2002: Standard for Learning Object Metadata (LOM) The IEEE 1484-12.1-2002: Standard for Learning Object Metadata can be obtained from IEEE, http://www.ieee.org IMS Control Documents The W3C XML Schema 1.0 Control Document, imsrdceo_rootv1p0.xsd, is located at: http://www.imsglobal.org/xsd/imsrdceo_rootv1p0.xsd IMS PLID Handbook IMS Persistent, Location-Independent, Resource Identifier Implementation Handbook version 1.0, [IMSPLID] http://www.imsglobal.org/implementationhandbook/imsrid_handv1p0.html ISO/IEC 10646 ISO (International Organization for Standardization). ISO/IEC 10646-1993 (E). Information technology -- Universal Multiple-Octet Coded Character Set (UCS) -- Part 1: Architecture and Basic Multilingual Plane. [Geneva]: International Organization for Standardization, 1993 (plus amendments AM 1 through AM 7). RFCs RFC 1648, A URN namespace for IETF documents, http://www.ietf.org/rfc/rfc1648.txt RFC 1766, Tags for the Identification of Languages, http://www.ietf.org/rfc/rfc1766.txt (this is now made obsolete by RFC 3066) RFC 2044, UTF-8, a transformation format of Unicode and ISO 10646, http://www.ietf.org/rfc/rfc2044.txt RFC 2141, URN Syntax, http://www.ietf.org/rfc/rfc2141.txt RFC 2396, Uniform Resource Identifiers (URI): Generic Syntax, http://www.ietf.org/rfc/rfc2396.txt RFC 3066, Tags for the Identification of Languages, http://www.ietf.org/rfc/rfc3066.txt Unicode The Unicode Consortium. The ff Standard, Version 2.0. Reading, Mass.: Addison-Wesley Developers Press, 1996. XML XML Schema Part 0: Primer, W3C Recommendation, 2 May 2001: http://www.w3.org/TR/xmlschema-0/ XML Schema Part 1: Structures, W3C Recommendation, 2 May 2001: http://www.w3.org/TR/xmlschema-1/ XML Schema Part 2: Datatypes, W3C Recommendation, 2 May 2001: http://www.w3.org/TR/xmlschema-2/ XML Version 1.0 Specification of the W3C: http://www.w3.org/TR/1998/REC-xml-19980210 XML Namespace Recommendation of W3C: http://www.w3.org/TR/1999/REC-xml-names-19990114부속서 B (참고)
1 There are multiple XSD files released with this specification, as described in section 3. 2 ALL conditions and requirements of the Information Model apply to the binding. These notes describe particular facets of the XML binding or additional restrictions on the element content imposed by the binding.해설
이 해설은 본체 및 부속서에 규정ㆍ기재한 사항 및 이것에 관련된 사항을 설명하는 것으로 표준의 일부는 아니다. 1. 제정의 취지 이러닝 서비스 다양화 및 고도화에 따라 이러닝 표준에 대한 필요성과 수요가 나날이 급증하고 있으며, 나아가 표준화를 지향하고 있는 국내외적 요구와 환경에 대응하기 위한 기반 마련이 시급하다. 또한, 국제 이러닝 표준화 분야에서 선진국간의 치열한 경쟁이 심화되고 있는 시점에서 국내 산업 및 국가 지식경쟁력 강화를 위한 실천적 차원의 표준화 추진 사례가 부족한 실정이다. 따라서 이러닝 표준화 요소 중 글로벌 경쟁력을 갖춘 어휘 교환 표준을 우선 단체표준으로 제안함으로써 산업 경쟁력 및 교육경쟁력 강화를 도모하고자 한다. 효율적인 단체표준 개발을 위해 IMS 어휘 교환 표준을 인용하였다. 2. 제정의 경위- 제1차 개발위원회(2009.1.): 단체표준 개발을 위한 참여 전문가를 위촉하고 규격 제정 취지와 규격의 제정 방향을 설정하였고, 초안 작성 기준을 토의하였다.
- 제2차 개발위원회(2009.3.): IMS GLC의 이러닝 표준을 기초로 작성한 초안을 통하여 부합화에 적합한 표준 용어를 정의하였다.
- 제3차 개발위원회(2009.5.): 기초(안)을 작성하여 적용범위, 인용표준, 용어정의 등의 내용을 검토하고, 참여진의 표준의 이해도를 높이기 위해 규격에 대한 검수 작업을 실시 하였다.
- 제4차 개발위원회(2009.6.): 표준 수정(안)을 토대로 IMS Korea 표준화 포럼의 표준 심사위원회를 통하여 표준을 검토하고 의견을 수렴하였다.
- 인용 표준의 형식은 KS A 0001의 구성에 맞게 조정하며, 연도는 삭제한다. (2009년 6월)
- 표준 규격서의 목차는 적용 범위 인용표준, 용어 정의 순으로 목차를 정렬 하며, 단, 원문에 서론이 있는 경우 서론은 유지한다. (2009년 6월)
- NETg, Boein Coporation와 같은 고유한 회사명은 A, B 형태의 가칭으로 대체 표기한다. (2009년 6월)
- 그림, 표, 본문 등에 포함된 영어를 최대한 번역하여 국문으로 표기한다. (2009년 10월)
- MS GLC의 표준 인용 정책에 의하여 페이지의 'IPR 공지’ 및 'IMS 로고’ 적용은 현행을 유지하며, 규격의 매 페이지마다 포함된 copyright 표기 문구는 삭제한다. (2009년 10월)
- 규격에 해설서(제정의 취지 등) 내용을 추가 작성한다. (2009년 10월)
표준개발 참여자(경칭생략, 무순)
|
성 명 |
근 무 처 |
직 위 |
|
조용상 |
한국교육학술정보원 |
팀장 |
|
김종현 |
계원디자인예술대학 |
교수 |
|
김현진 |
한국교원대학교 |
교수 |
|
정광식 |
한국방송통신대학교 |
교수 |
|
황대준 |
성균관대학교 |
교수 |
|
고영승 |
(주)디유넷 |
대리 |
|
이정우 |
(주)포씨소프트 |
차장 |
|
장근원 |
(주)크레듀 |
과장 |
|
정호원 |
(주)씨티유니온 |
차장 |
|
지승환 |
테크빌닷컴(주) |
차장 |
|
최성기 |
SK C&C |
과장 |
|
권영진 |
한국교육학술정보원 |
연구원 |
|
최미애 |
한국교육학술정보원 |
연구원 |